はじめに
みなさんこんにちは。社内でHeroku推進活動をしている溝井です!
ブログでも過去数回Herokuに関する記事を投稿しております。
当ブログはSalesforceの内容を期待してご覧になられた方がほとんどかと思います。
そこで今回はHerokuとSalesforceどちらかでも利用可能なAI、
「Einstein Vision」を取り上げてみたいと思います!
Herokuに興味がない方も是非最後までお付き合い頂ければと思います。
また非常に長い記事になってしまったので、雰囲気だけつかみたい方は、
後半の「動作確認」セクションのGIFイメージやサンプルアプリをご確認頂ければと思います!
Einstein Visionとは?
以下にあるようにセールスフォース・ドットコム社が提供する画像認識に関するAPI群となります。
Einsteinのコンセプトどおり簡単にAIの機能を利用することができます。
この度セールスフォース・ドットコムは、パワフルな新しいAPI群である「Einstein Vision」の提供を開始します。これにより、Force.comやHerokuの開発者といったあらゆるスキルセットの方々が、CRMに画像認識を活用したり、AI(人工知能)を組み込んだアプリの開発を迅速に行うことを可能にします。セールス、サービス、マーケティング部門を横断したエンドユーザーがよりスマートに、さらにプレディクティブに業務を行えるようにするために、開発者はあらかじめ学習済みの画像認識器を活用したり、あるいは自身で認識器をトレーニングして様々な画像認識の課題を解決することが可能になります。
2017 Salesforce Einsteinのカタチ Vol.1 Einstein Visionが登場 画像認識技術がより身近により引用
Herokuで「Einstein Vision」
先日開催されたHerokuのイベント「Heroku Meetup #17 Heroku Strike」に参加してきました。
その時の懇親会LTで以下のサンプルアプリのデモがとてもおもしろかったのでご紹介させて頂きます。
Herokuへデプロイ
ここから先はHerokuアカウントがある場合の前提で進めさせて頂きます。
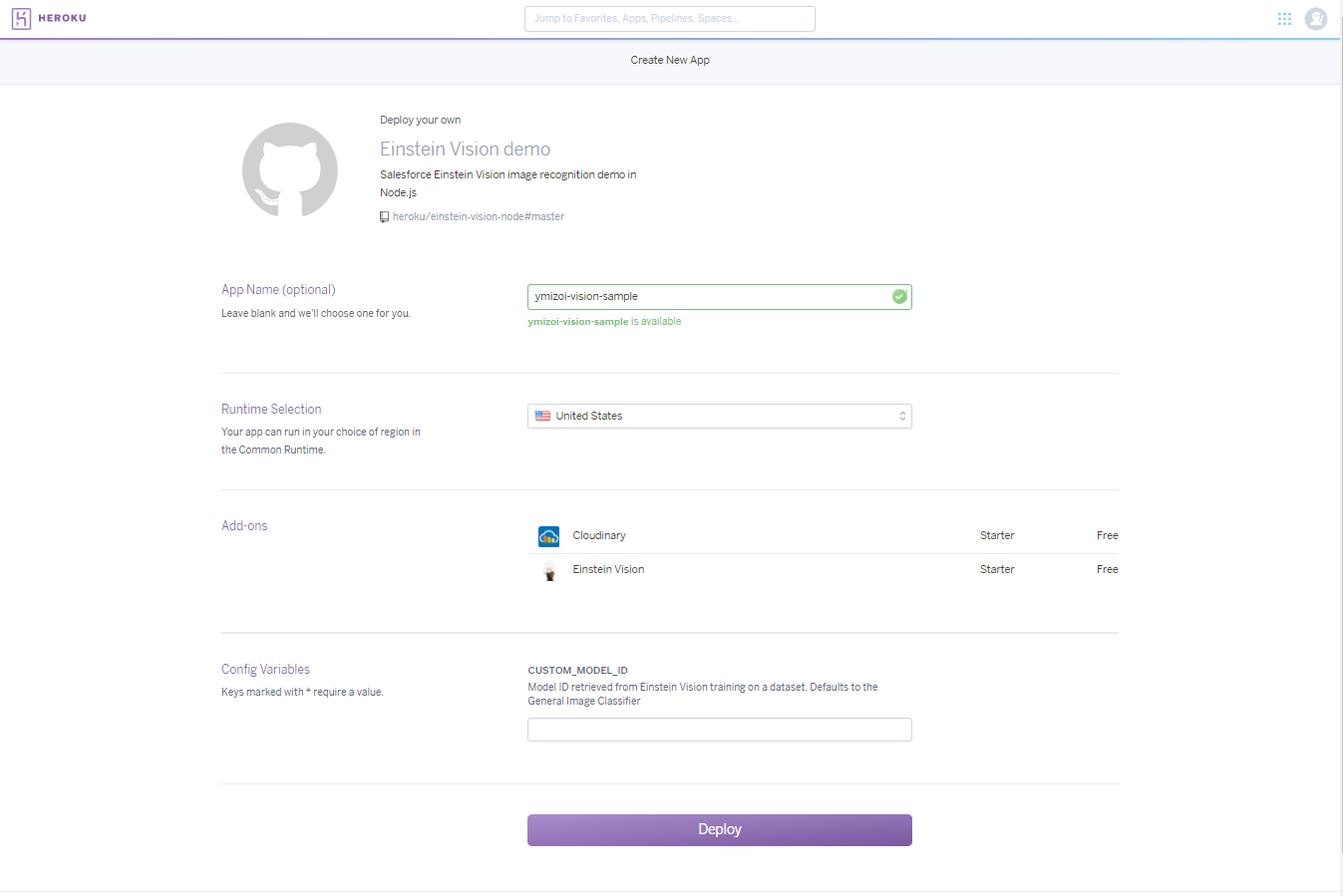
サンプルアプリのGithubに遷移します。
ページ中程のHerokuボタン「Deploy to Heroku」をクリック。

アプリ名を入力して「Deploy」をクリック。
以上!
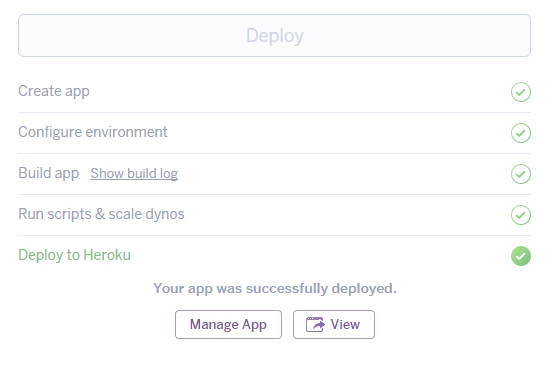
上記作業だけであっという間に自分のHerokuアカウントにサンプルアプリがデプロイされます。
「View」ボタンで登録されたアプリを起動してみましょう。
サンプルアプリが利用可能になりました。
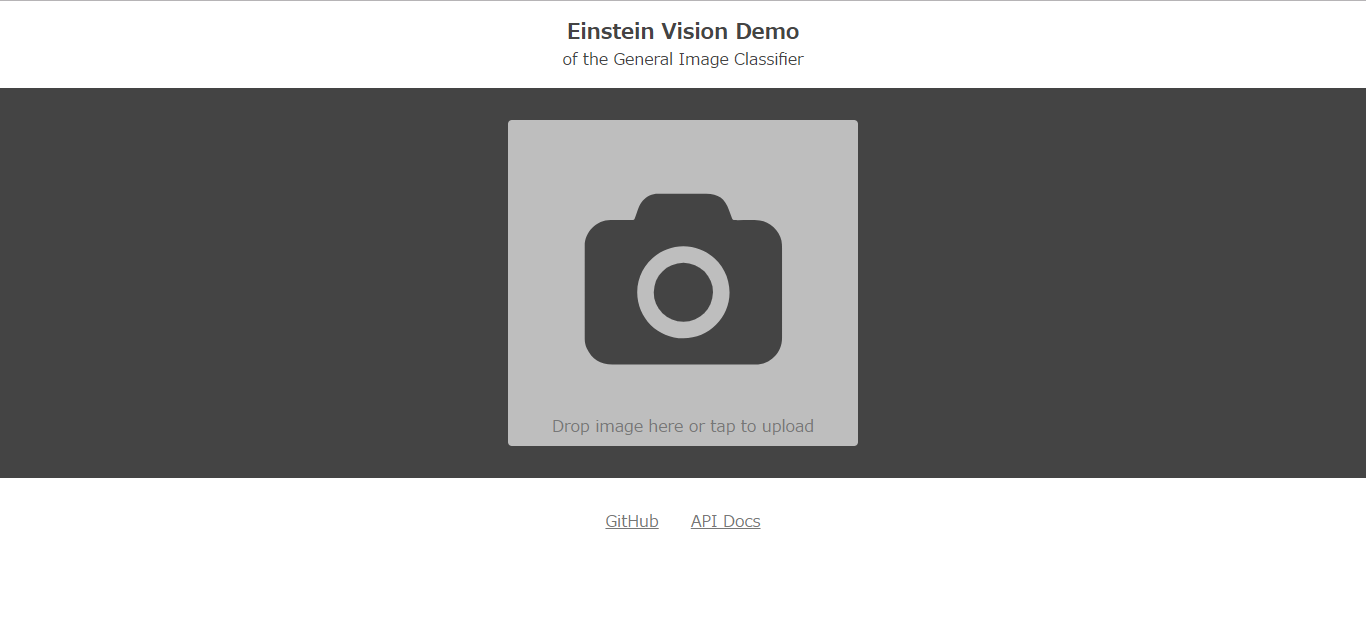
試しに画像をアップロードしてみます!
サンプルアプリでは「Einstein Vision」が提供している予測・解析モデルの「General Image Classifier」というモデルが利用されています。
モノを対象とした画像認識を行い、予測結果が返却されます。
今回は手元にあった腕時計の画像をアップロードしてみました。
結果は「analog clock」の可能性が49%でほぼ正解です!なかなかおもしろいです!

サンプルアプリの詳細確認
ではアプリの詳細を確認していきたいと思います。
Herokuボタンでデプロイする際にも表示されていましたが、サンプルアプリには2つのアドオンが利用されています。
- Cloudinary
- 画像処理に利用
- Einstein Vision
- Einstein Visionを使うために利用
アドオンが登録されたタイミングでアプリの環境変数に以下の値がセットされています。
- CLOUDINARY_URL
- EINSTEIN_VISION_ACCOUNT_ID
- EINSTEIN_VISION_PRIVATE_KEY
- EINSTEIN_VISION_URL
ここで重要なのは「EINSTEIN_VISION_ACCOUNT_ID」と「EINSTEIN_VISION_PRIVATE_KEY」となります。
上記のアドオンを追加したタイミングで「Einstein Vision」を利用するためのアカウント情報が作成され、
環境変数に登録されているということになります。
Einstein Visionを使いこなす
サンプルアプリで作成されたアカウントを用いて、Einstein VisionのAPIを触っていこうと思います。
参考:リファレンス
リファレンスを読み進めていくとApexからEinsteinを利用する手順が記載されていますが、今回はHerokuで利用するための手順を抜粋してご紹介させて頂きます。
1.アクセストークンの取得
token取得用サイトでHerokuアプリに設定された環境変数の「Einstein Vision」のアカウント情報からアクセストークンを発行します。
まずはHerokuアプリの環境変数を確認します。
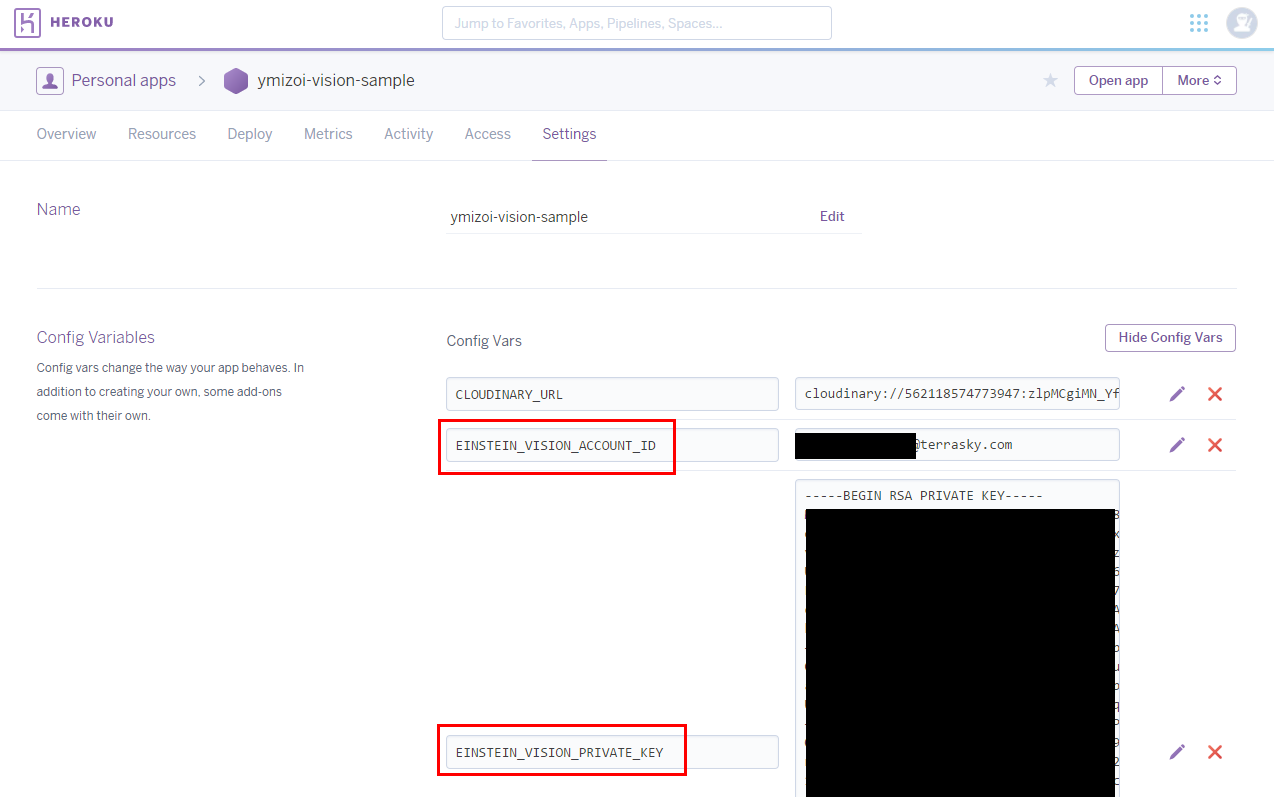
上記で確認したHerokuアプリの環境変数の情報を元に、
token取得用サイトで以下の項目を設定して「GET TOKEN」ボタンをクリックします。
| 設定項目 | 設定値 |
| Email or Account ID | Herokuアプリの環境変数「EINSTEIN_VISION_ACCOUNT_ID」の値 |
| Private Key | Herokuアプリの環境変数「EINSTEIN_VISION_PRIVATE_KEY」の値 |
| Expiration in Mins | 任意の分数 |

アクセストークンが取得できました。
2.データセットの確認
ここからはWindowsでGitをインストールする際に利用できるようになるGit BASHを利用して操作をしていきます。
またレスポンス結果の値は見やすいように一部整形しております。
コマンドラインの操作でアクセストークンを多用するので変数化しておきます。
$ mytoken=先程取得したアクセストークン
以下のコマンドで設定した変数が反映されているか確認できます。
$ echo $mytoken
ではさっそく以下のAPIにて現在のデータセットの一覧を確認してみます。
$ curl -X GET -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" https://api.einstein.ai/v1/vision/datasets
まだデータセットを作成していなので1件もありません。
{
"object": "list",
"data": []
}
3. ZIPファイル準備
今回はロゴ画像をアップロードしたら、会社のロゴなのか、製品のロゴなのかを判定してくれる独自の予測・解析モデルを作ってみたい思います。
以下の様な構成のZIPファイルを用意します。
icon
├terrasky
└terrasky-products
※「terrasky」フォルダには弊社のロゴ画像を40枚以上格納
※「terrasky-products」には弊社製品のロゴ画像を40枚以上格

次の手順で利用するAPIにより、
ルートディレクトリの「icon」がデータセット名となり、
各ディレクトリの名称がラベルとなります。
最低限2つのラベルが必要で、一つのラベルには40以上のサンプルが必要となります。
はじめは用意するZIPファイルの構成やAPIの仕様がわからず苦戦しましたが、
以下のウェビナーの資料が大変参考になりました。
4.データセットの作成
Create a Dataset From a Zip File Asynchronously
引数の「data」には「icon.zip」を格納している任意のパスを指定して下さい。
$ curl -X POST -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" -H "Content-Type: multipart/form-data" -F "data=@C:\path\to\icon.zip" https://api.einstein.ai/v1/vision/datasets/upload
以下のようなレスポンスが返ってきます。
{
"id": 1005089,
"name": "icon",
"createdAt": "2017-06-27T07:23:48.000+0000",
"updatedAt": "2017-06-27T07:23:48.000+0000",
"labelSummary": {
"labels": []
},
"totalExamples": 0,
"available": false,
"statusMsg": "UPLOADING",
"type": "image",
"object": "dataset"
}
上記の"available":false,"statusMsg":"UPLOADING"とあるように上記のAPIは非同期処理のため、まだデータセット作成が完了していない状況となります。
データセットのidはこの後も利用するため、変数化しておきます。
$ datasetid=1005089 $ echo $datasetid
5. データセットのステータス確認(データセット一覧再取得)
$ curl -X GET -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" https://api.einstein.ai/v1/vision/datasets
以下の様なレスポンスが返ってきます。
{
"object": "list",
"data": [
{
"id": 1005089,
"name": "icon",
"createdAt": "2017-06-27T07:07:41.000+0000",
"updatedAt": "2017-06-27T07:07:43.000+0000",
"labelSummary": {
"labels": [
{
"id": 24066,
"datasetId": 1005089,
"name": "terrasky",
"numExamples": 40
},
{
"id": 24067,
"datasetId": 1005089,
"name": "terrasky-products",
"numExamples": 41
}
]
},
"totalExamples": 81,
"totalLabels": 2,
"available": true,
"statusMsg": "SUCCEEDED",
"type": "image",
"object": "dataset"
}
]
}
上記のとおり、"available":true,"statusMsg":"SUCCEEDED"となり準備が完了致しました。
5.トレーニング
モデル名を設定する必要があるため変数化して設定しておきます。
$ modelname="Icon Model" $ echo $modelname
トレーニングの処理を実施します。
$ curl -X POST -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" -H "Content-Type: multipart/form-data" -F "name=$modelname" -F "datasetId=$datasetid" https://api.einstein.ai/v1/vision/train
以下の様なレスポンスが返ってきます。
{
"datasetId": 1005089,
"datasetVersionId": 0,
"name": "Icon Model",
"status": "QUEUED",
"progress": 0,
"createdAt": "2017-06-27T07:40:20.000+0000",
"updatedAt": "2017-06-27T07:40:20.000+0000",
"learningRate": 0,
"epochs": 0,
"queuePosition": 1,
"object": "training",
"modelId": "RT5FVCCFFTZRXQK5I2PCSBPZZY",
"trainParams": null,
"trainStats": null,
"modelType": "image"
}
こちらも非同期処理のため、実行直後のステータスは"status":"QUEUED"となり、完了まで少し時間がかかります。
私の場合は5~10分もかからなかったかと思います。
この時、modelIdが返却されているため、変数化しておきます。
$ modelId=RT5FVCCFFTZRXQK5I2PCSBPZZY $ echo $modelId
6.トレーニング結果を確認
$ curl -X GET -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" https://api.einstein.ai/v1/vision/train/$modelId
完了していないと以下の様に"status":"RUNNING"のままとなります。
もう少し時間をおいて上記のコマンドを実行してみます。
{
"datasetId": 1005089,
"datasetVersionId": 2613,
"name": "Icon Model",
"status": "RUNNING",
"progress": 0.67,
"createdAt": "2017-06-27T07:24:49.000+0000",
"updatedAt": "2017-06-27T07:25:57.000+0000",
"learningRate": 0.001,
"epochs": 3,
"object": "training",
"modelId": "RT5FVCCFFTZRXQK5I2PCSBPZZY",
"trainParams": null,
"trainStats": null,
"modelType": "image"
}
完了していると以下の様なレスポンスが返ってきます。
{
"datasetId": 1005089,
"datasetVersionId": 2614,
"name": "Icon Model",
"status": "SUCCEEDED",
"progress": 1,
"createdAt": "2017-06-27T07:40:20.000+0000",
"updatedAt": "2017-06-27T07:41:46.000+0000",
"learningRate": 0.001,
"epochs": 3,
"object": "training",
"modelId": "RT5FVCCFFTZRXQK5I2PCSBPZZY",
"trainParams": null,
"trainStats": {
"labels": 2,
"examples": 81,
"totalTime": "00:01:23:120",
"trainingTime": "00:01:21:335",
"earlyStopping": false,
"lastEpochDone": 3,
"modelSaveTime": "00:00:01:781",
"testSplitSize": 6,
"trainSplitSize": 75,
"datasetLoadTime": "00:00:01:785"
},
"modelType": "image"
}
7.予測
いよいよトレーニングした独自の予測・解析モデルを用いた画像認識処理を実行します!
このテストでは弊社のロゴ画像をアップロードしてみます。

※引数の「sampleContent」には予測対象の画像ファイルの格納先を指定して下さい。
$ curl -X POST -H "Authorization: Bearer $mytoken" -H "Cache-Control: no-cache" -H "Content-Type: multipart/form-data" -F "sampleContent=@C:\path\to\terrasky-icon.png" -F "modelId=$modelId" https://api.einstein.ai/v1/vision/predict
結果は以下のとおりとなり、terraskyでラベルである可能性が「0.99955267」、terrasky-productsである可能性が「4.4736138E-4」となりterraskyラベルに限りなく適した画像であると認識されました!
{
"probabilities": [
{
"label": "terrasky",
"probability": 0.99955267
},
{
"label": "terrasky-products",
"probability": 0.00044736138
}
],
"object": "predictresponse"
}
サンプルアプリに適用
サンプルアプリのREADME.mdにも記載されていますが
サンプルアプリは自分で作成したカスタムのデータモデルを利用できるようになっています。
せっかくなので上記で作成したデータモデルを適用させてみたいと思います。
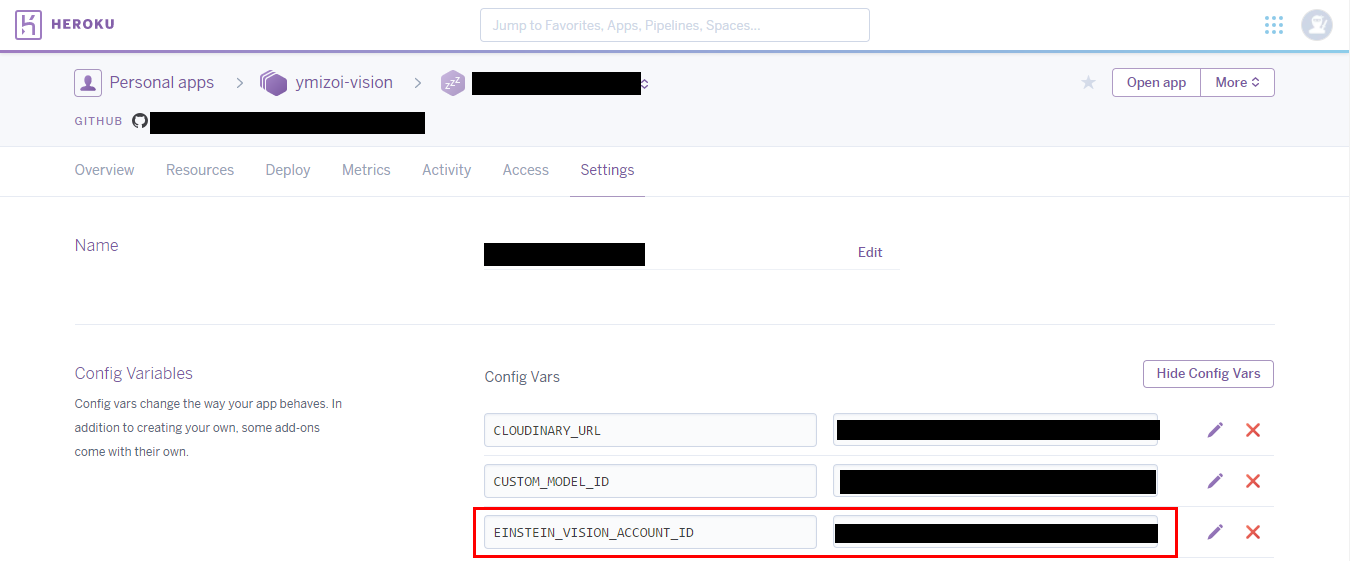
環境変数の設定
「CUSTOM_MODEL_ID」に先程トレーニングしたmodelIdを設定します。
以上!!!
とっても簡単ですね!
動作確認
せっかくなので今回作成した独自の予想・解析モデルを利用して、デモアプリを弊社仕様にブランディングして実装してみました。
元のアプリとの挙動を比較してみましょう!
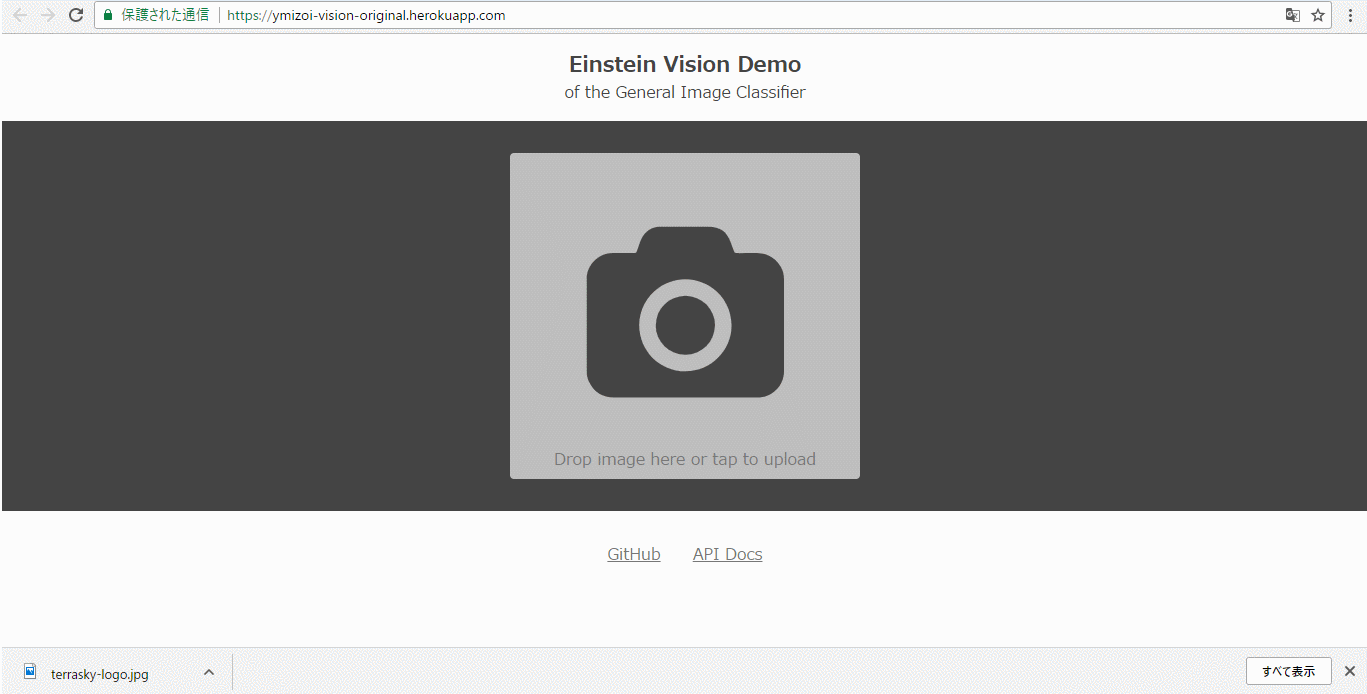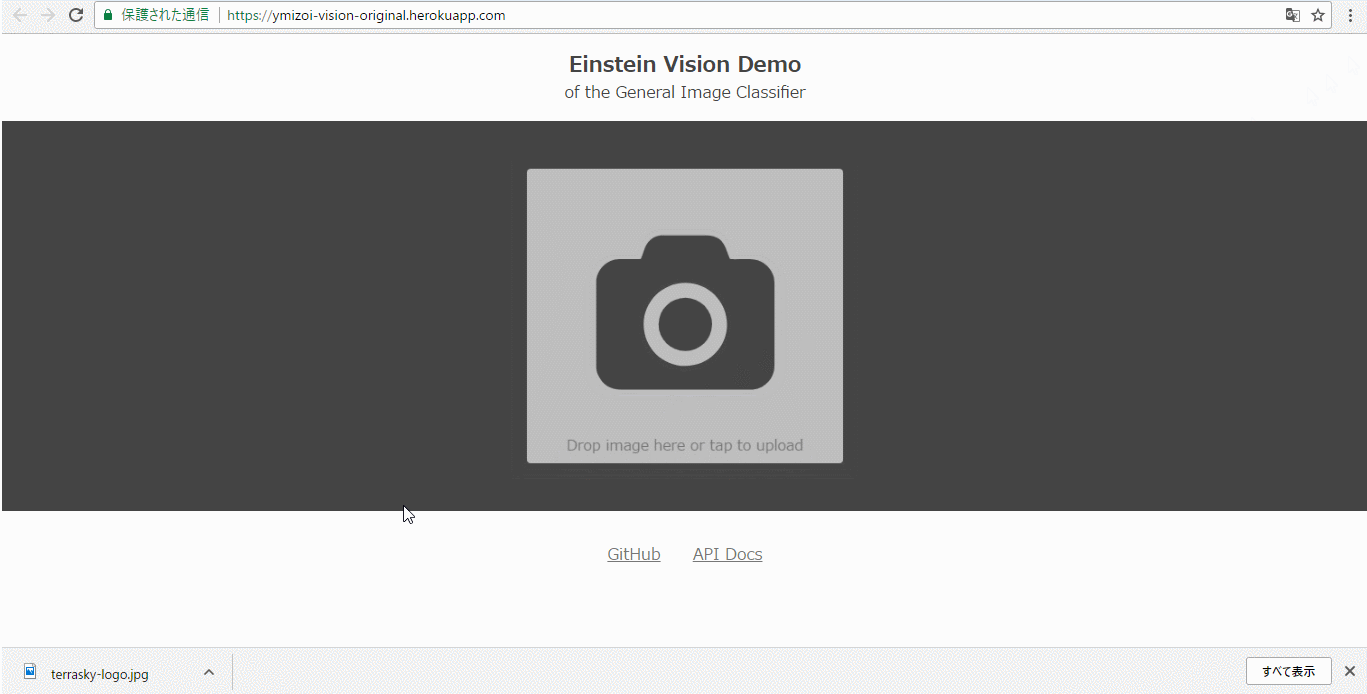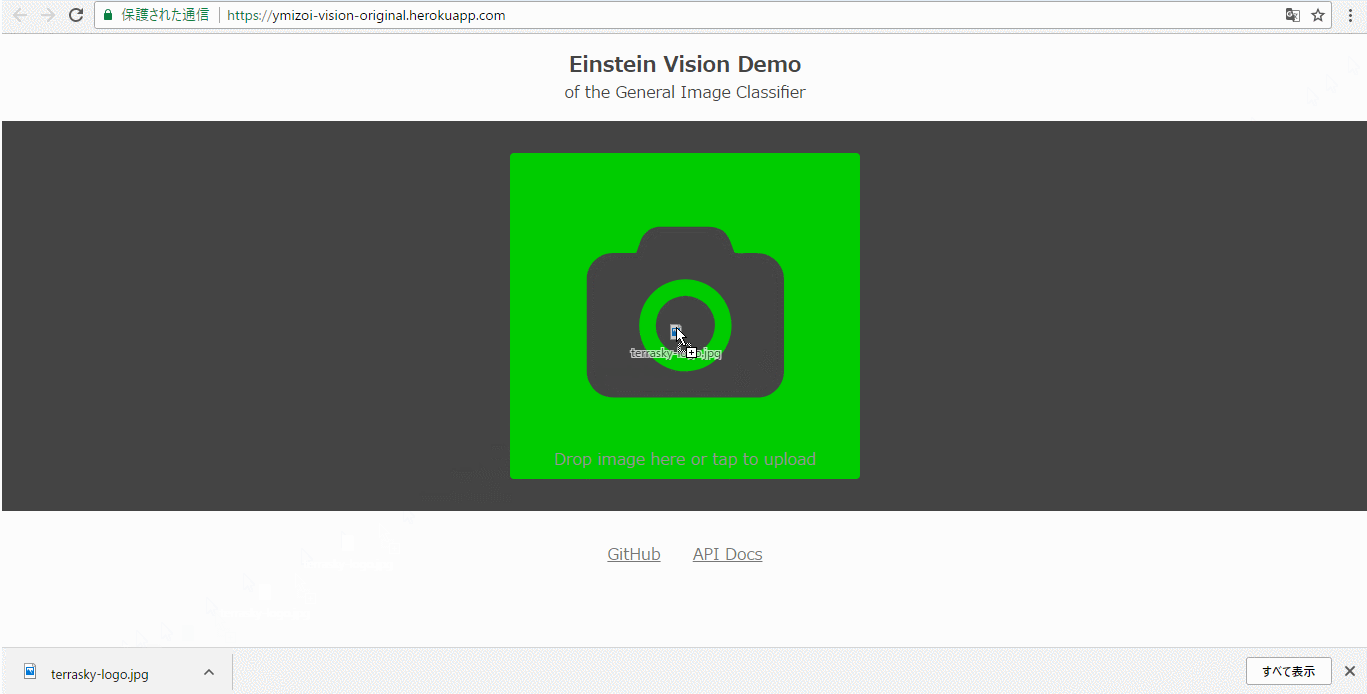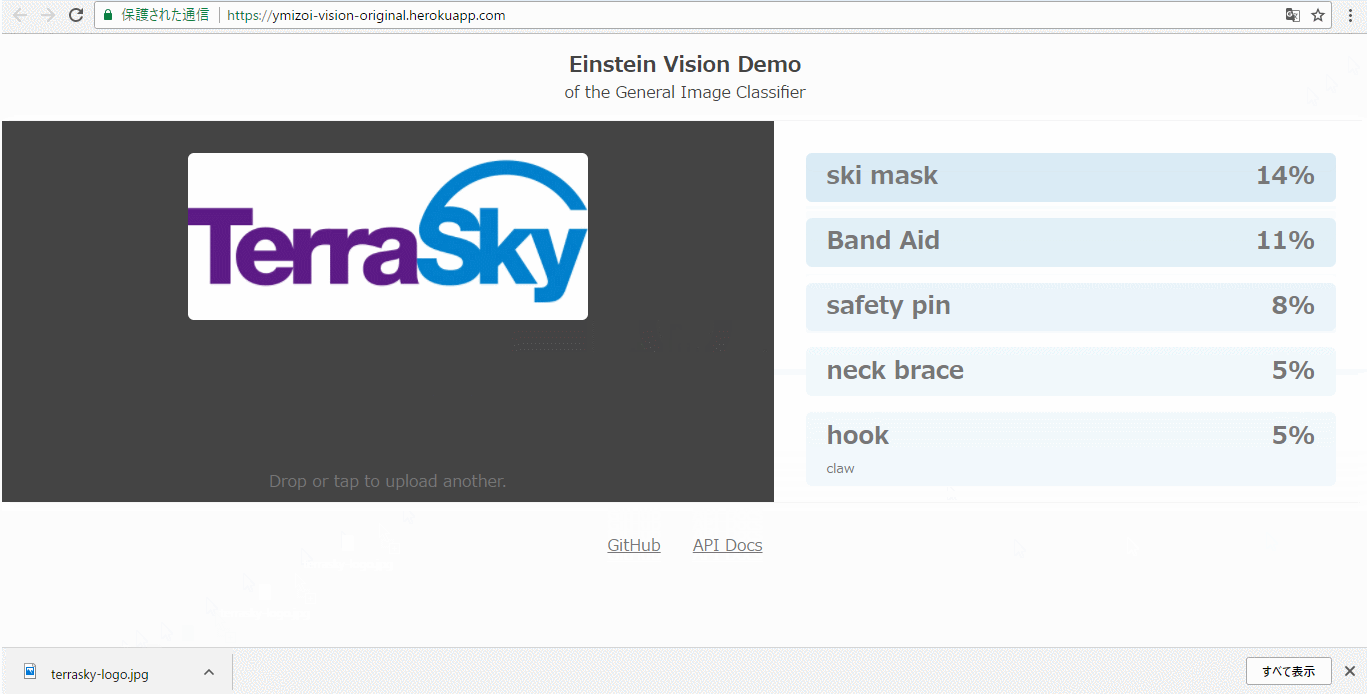
元のサンプルアプリ(General Image Classifier)
https://ymizoi-vision-original.herokuapp.com/
TerraSkyのロゴを分析すると「ski mask(スキーマスク)」と認識されてしまいます。
独自の予測・解析モデルを利用したアプリ(Custom Image Classifier)
https://ymizoi-vision.herokuapp.com/
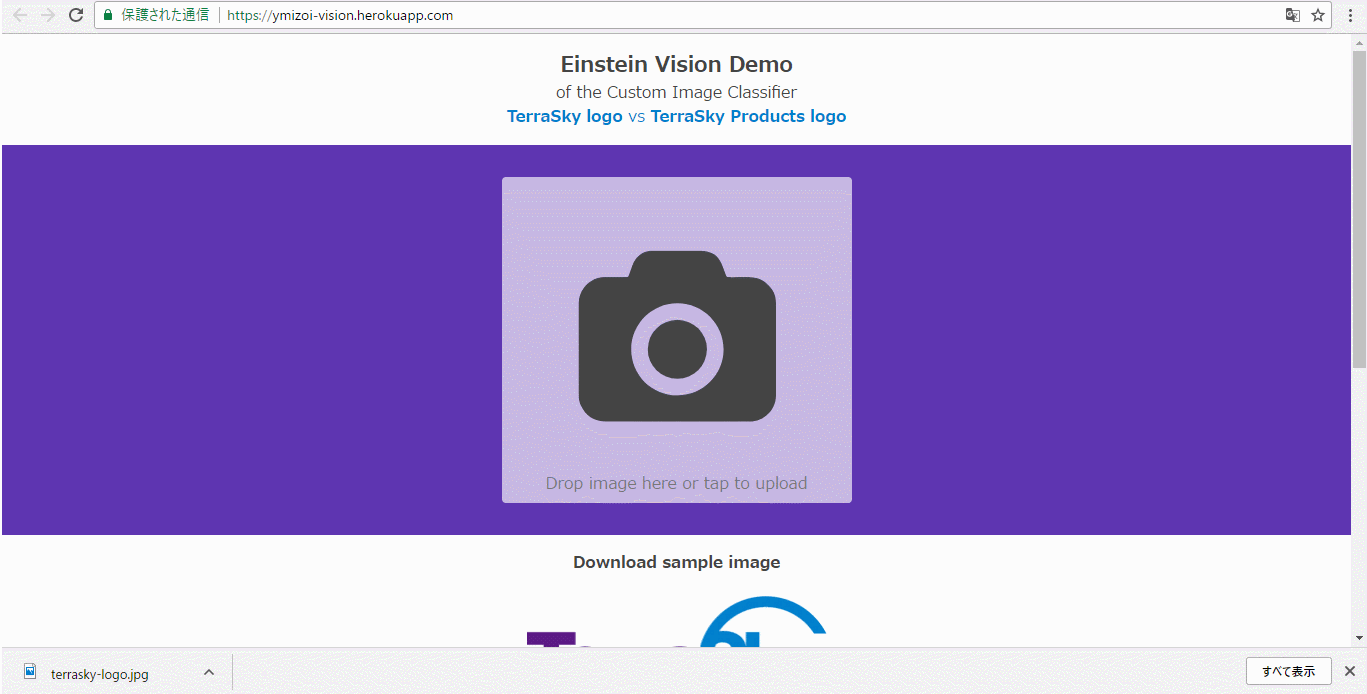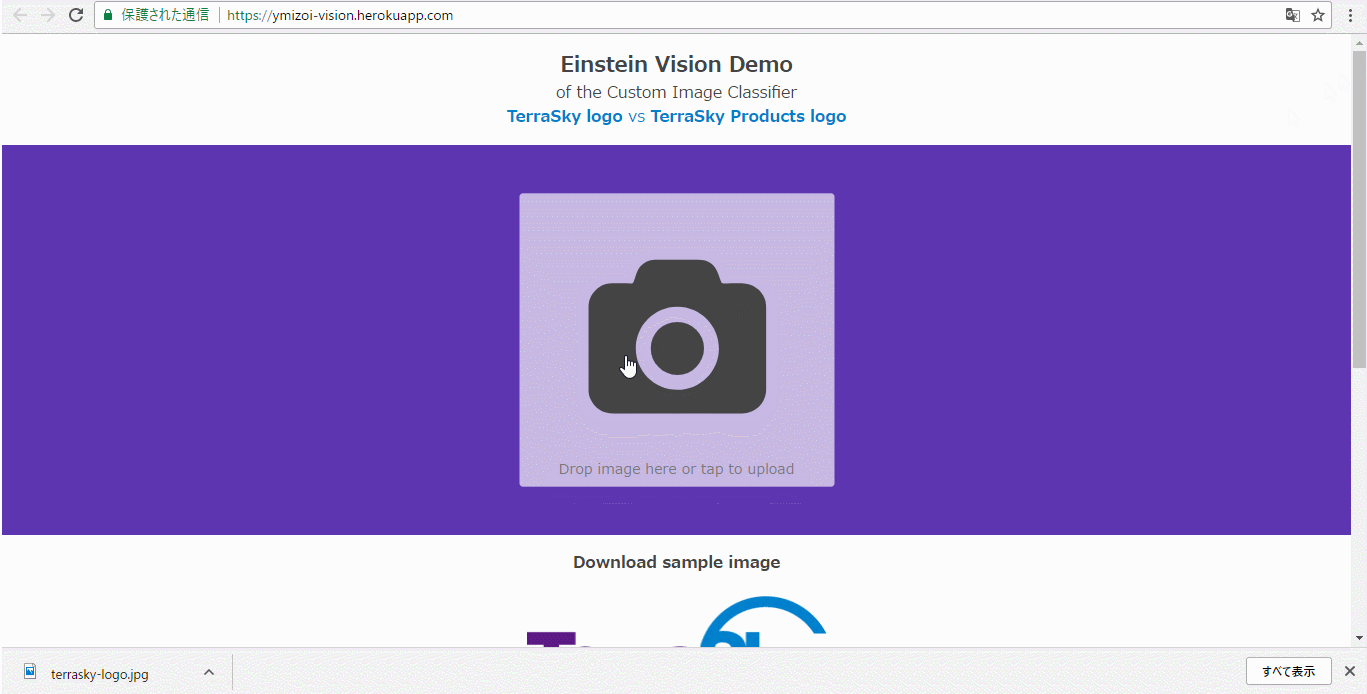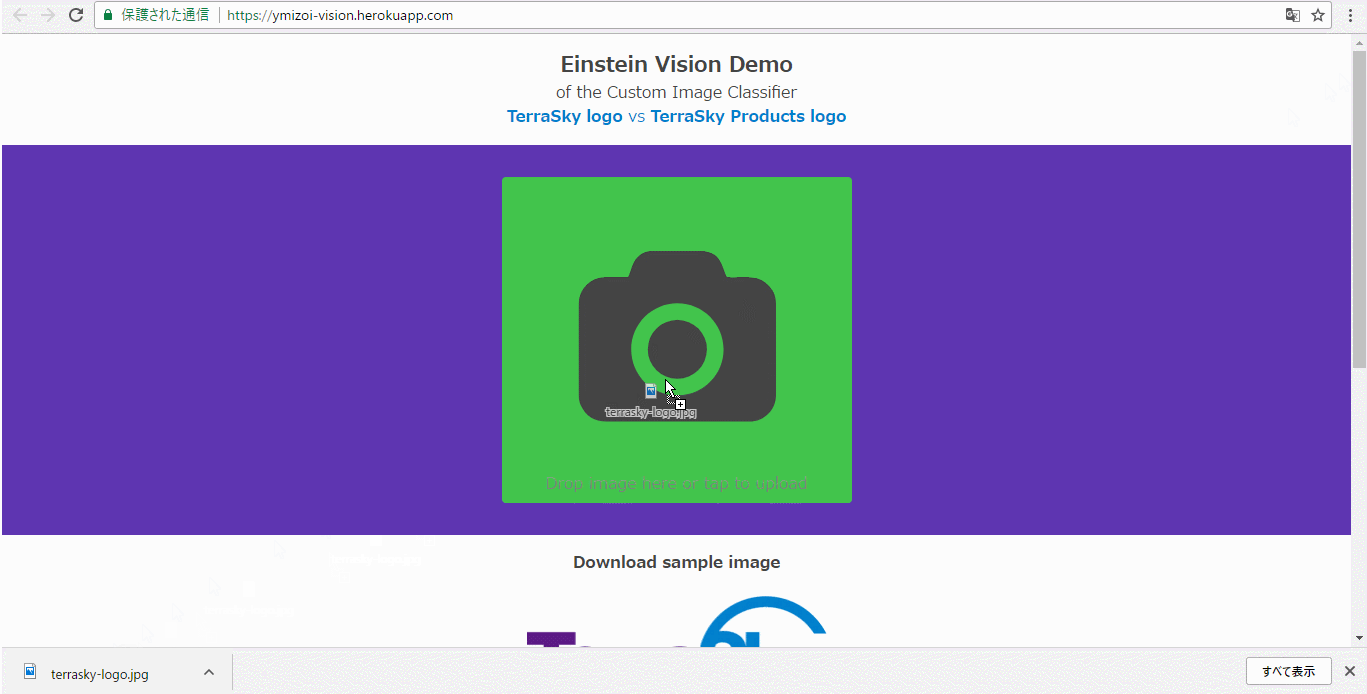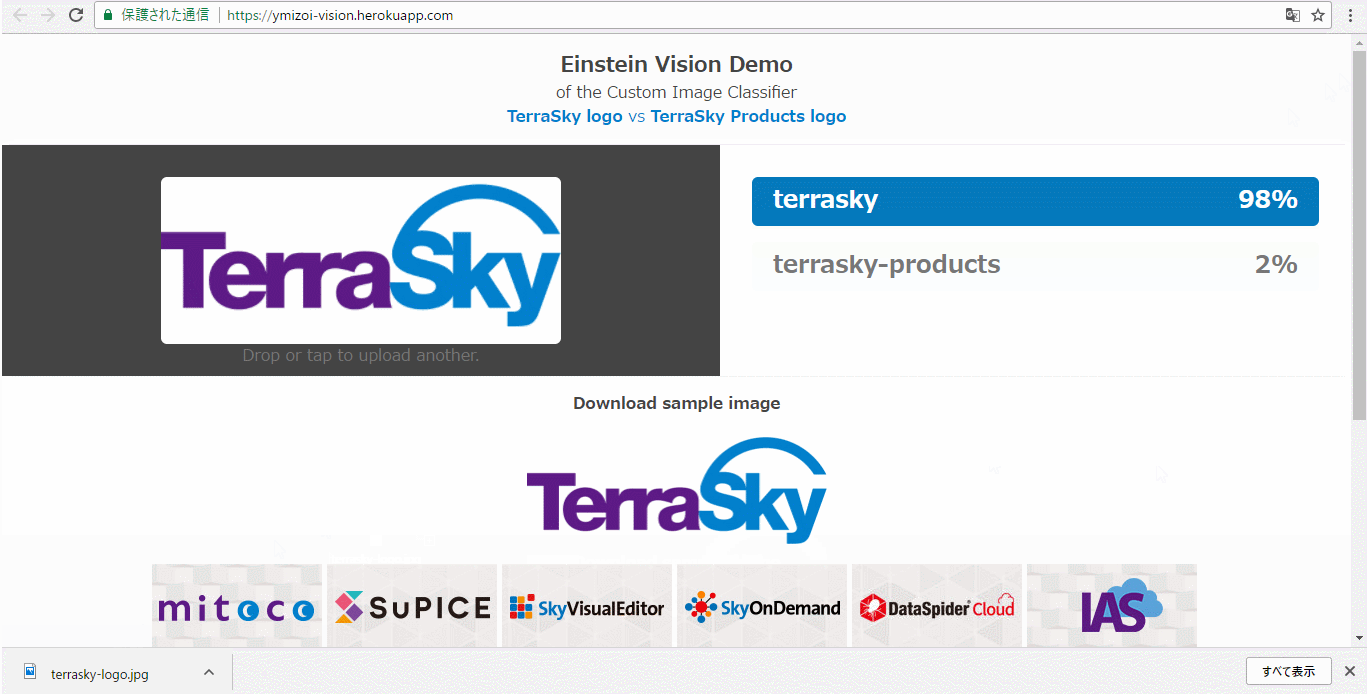
しっかりとTerraSkyと認識されました。
ちなみに製品ロゴの方で試してみても、トレーニングした内容でしっかりと認識してくれました!
まとめ
簡単なサンプルですが非常に短い手順でカスタムの画像認識のデータモデルを作成することが出来ました!
他のAPIなどもいろいろ試してみて、今後はより精度の高い画像認識ができるようにしてみたいと思います!
※今回は2つのラベルだけで作成したので、あくまでどちらかのラベルに近い方への認識結果を返却されるようになっています。
※全然関係ない画像をアップロードするとどちらか近い方の結果に偏ります。
サンプルなのであまり精度は高く無いかもしれませんが、
ぜひ上記のアプリで弊社のロゴ画像や製品画像が写り込んだイベントの写真をアップして、
EinsteinのAI機能を体感して頂ければと思います!
まだイベントの写真をお持ちでない方はサンプル画像で試して頂くか、
7月に開催される弊社イベント「TerraSky Day 2017」にお申込み頂き、写真を撮りに来て頂けると幸いです!
*** 追記 ***
当ブログ執筆後で公開前のタイミングで、Salesforce 開発者および管理者向けの有償イベント「TrailheaDX」にて「Einstein Platform Service」に関して発表がありました。
概要は「Salesforce Developers Japan Blog」に記載されておりますが、文章に関する2つ新機能が追加になりました!
- Einstein Sentiment - 文章をポジティブ、ネガティブ、ニュートラルに類推する
- Einstein Intent - 文章を独自のカテゴリで類推する
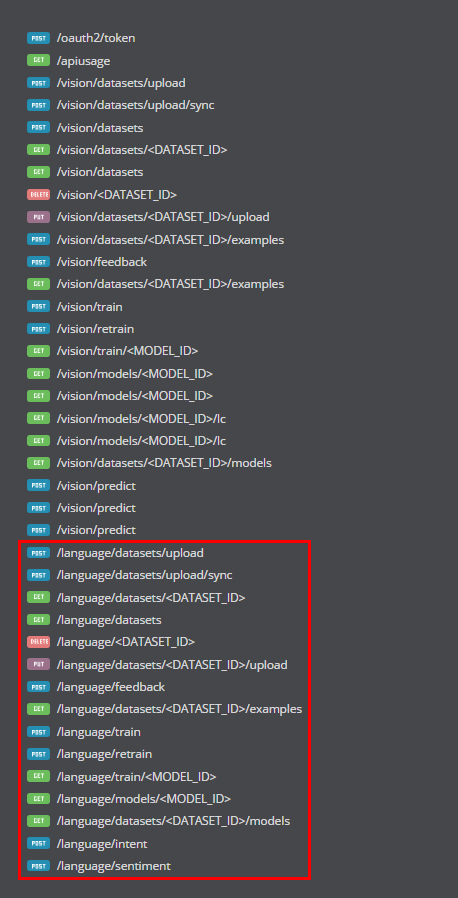
さっそく、リファレンスを見ると「language」に関するAPIが追加されていました!
今後も新たなAPIに期待して、積極的に検証していきたいと思います!